
In this post I share how I built a simple CI/CD pipeline powered by GitHub Actions to build, test and deploy a Python application to DigitalOcean, but it can be applied to any server with SSH.
CI/CD with GitHub Actions
Because I hate long blog posts with the vital information right in the middle, I’m going to share my .yml file and let you decide whether you need to read the rest of the post, or not. Sometimes the source code is enough.
name: Deploy to production
on:
push:
branches: [ production ]
jobs:
deploy:
name: Deploy to production
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2.1.0
- name: Set up Python 3
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Prepare database
run: |
cd ./db
tar -zxvf appdb.tar.gz
- name: Run end-to-end tests
run: pytest
- name: Build app
run: python setup.py sdist
- name: Deploy build to production
run: |
mkdir $PWD/.ssh
eval "$(ssh-agent -s)"
echo -n "${{ secrets.SSH_KEY }}" > $PWD/.ssh/id_rsa
chmod 600 $PWD/.ssh/id_rsa
ssh-add -k $PWD/.ssh/id_rsa
ssh-keyscan -t ecdsa-sha2-nistp256 ${{ secrets.PROD_SERVER }} > $PWD/.ssh/known_hosts
ssh -o UserKnownHostsFile=$PWD/.ssh/known_hosts ${{ secrets.USER }}@${{ secrets.PROD_SERVER }} "
cd /home/app;
source envapp/bin/activate;
pip install app-1.tar.gz --upgrade;
touch wsgi.py;
sudo nginx -s reload;
"
rm $PWD/.ssh/id_rsa $PWD/.ssh/known_hosts
- name: Clear Sucuri's cache (WAF)
run: |
curl "https://waf.sucuri.net/api?v2" \
--data "k=${{ secrets.SUCURI_KEY }}" \
--data "s=${{ secrets.SUCURI_SITE_HASH }}" \
--data "a=clear_cache"Defining the GitHub Actions
Chances are you already know this, but in case you do not, GitHub gives you 2000 minutes per month to run GitHub Actions. And these actions can be whatever you program them to be. You can use them to build your project, run tests against it, and to deploy it. The sky’s the limit.
You can make use of GitHub Actions by creating a .github directory at the root of your project, creating a workflows directory inside it and describing your actions using .yaml/.yml files.
Let’s create a cicd.yml file inside .github/workflows. The simples of actions looks like this:
name: Deploy to production
on:
push:
branches: [ production ]
jobs:
deploy:
name: Deploy to production
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2.1.0
- name: Run ls command
run: lsThis action simply pulls the current repository in an Ubuntu container and executes the command “ls” in the current directory.
Using third-party GitHub Actions
Besides defining your own GitHub actions you also have the option to re-use actions defined by a third-party. In this case I’m using actions/setup-python@v2, which gives me a Python 2 and 3 without any of the effort.
You can check that your Python environment works OK by committing and pushing the following changes to the cicd.yml file.
name: Deploy to production
on:
push:
branches: [ production ]
jobs:
deploy:
name: Deploy to production
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2.1.0
- name: Set up Python 3
uses: actions/setup-python@v2
with:
python-version: '3.x'
run: python --versionDefining the steps for the CI/CD or workflow
GitHub actions take steps and execute them in order to complete the workflow.
In my case I have a Python application built on top of Flask and SQLite3, and currently running on DigitalOcean.
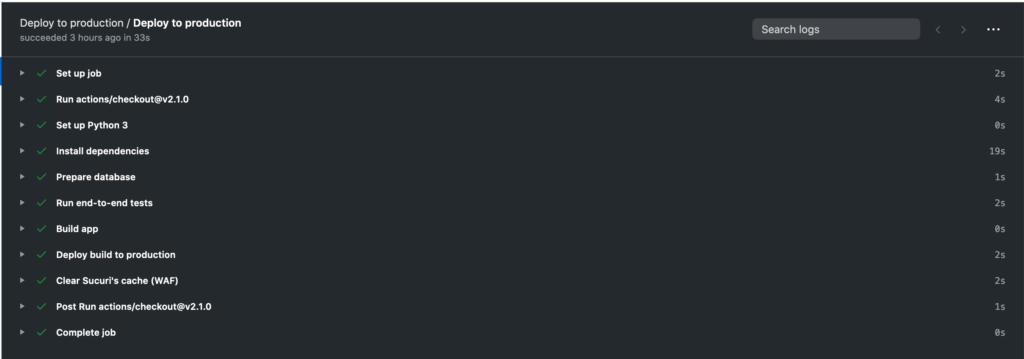
I needed a CI/CD to:
- Prepare the Python environment
- Install Python dependencies
- Prepare the database (the .sqlite3 file is compressed, I need to make it ready for the step 4)
- Run end-to-end tests (I need the production database for the tests)
- Build the app
- Deploy build to production
- Clear Sucuri’s cache (CDN/WAF)
This is how the first step “install Python dependencies” is going to look like in our cicd.yml file:
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txtI won’t explain the steps “prepare database” and “run end-to-end tests” since those are only needed for my application.
The “build app” step is just running “python setup.py sdist” to create the distribution file.
The interesting part comes in the “deploy build to production” step.
SSH to your server using GitHub Actions
While there are awesome third-party actions to connect the server handling your actions to your host, my needs were really simple and I didn’t feel like I needed them. I went for something more crafty.
First things first, I defined the following secrets in my GitHub repository:
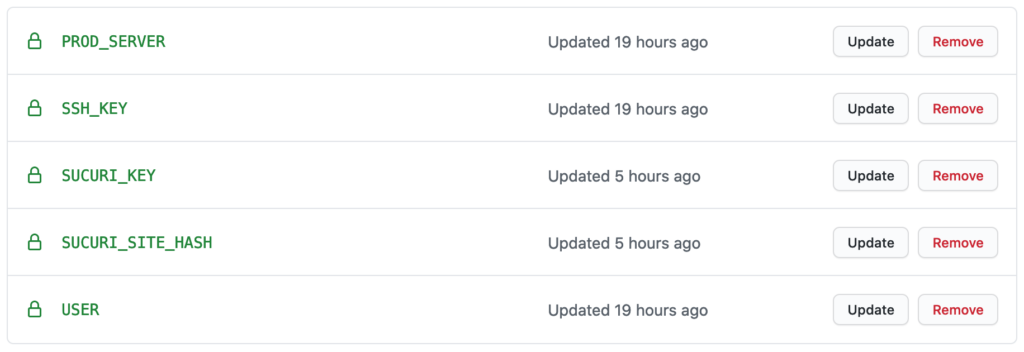
These secrets are available in your cicd.yml file as variables. You can access them with the syntax: ${{ secrets.SECRET_NAME }}
Here’s how I managed to authenticate the SSH connection from GitHub’s server to my DigitalOcean server:
mkdir $PWD/.ssh
eval "$(ssh-agent -s)"
echo -n "${{ secrets.SSH_KEY }}" > $PWD/.ssh/id_rsa
chmod 600 $PWD/.ssh/id_rsa
ssh-add -k $PWD/.ssh/id_rsa
ssh-keyscan -t ecdsa-sha2-nistp256 ${{ secrets.PROD_SERVER }} > $PWD/.ssh/known_hosts
ssh -o UserKnownHostsFile=$PWD/.ssh/known_hosts ${{ secrets.USER }}@${{ secrets.PROD_SERVER }} "
cd /home/app;
source envapp/bin/activate;
pip install app-1.tar.gz --upgrade;
touch wsgi.py;
sudo nginx -s reload;
"
rm $PWD/.ssh/id_rsa $PWD/.ssh/known_hostsPlease note that the type of the key I’m using for ssh-keyscan (ecdsa-sha2-nistp256) might not be what you need. Please read this page for more information.
Clearing my CDN/WAF cache
On successful deployments, I also need my CI/CD pipeline to clear the cache hosted on the CDN/WAF powered by Sucuri Security.
Doing so will ensure that my app users get to enjoy new features and content as soon as they are properly tested and deployed on the production server.
Doing this with GitHub Actions and Sucuri is really easy, all it takes is a curl call:
curl "https://waf.sucuri.net/api?v2" \
--data "k=${{ secrets.SUCURI_KEY }}" \
--data "s=${{ secrets.SUCURI_SITE_HASH }}" \
--data "a=clear_cache"And that completes my CI/CD pipeline powered by GitHub actions. More advanced needs will need a more advanced pipeline, but this one fits perfectly for my project. The whole pipeline runs in less than a minute.
If you have suggestions on how to improve this pipeline, ping me on Twitter.
Happy deploying to production! 🚀